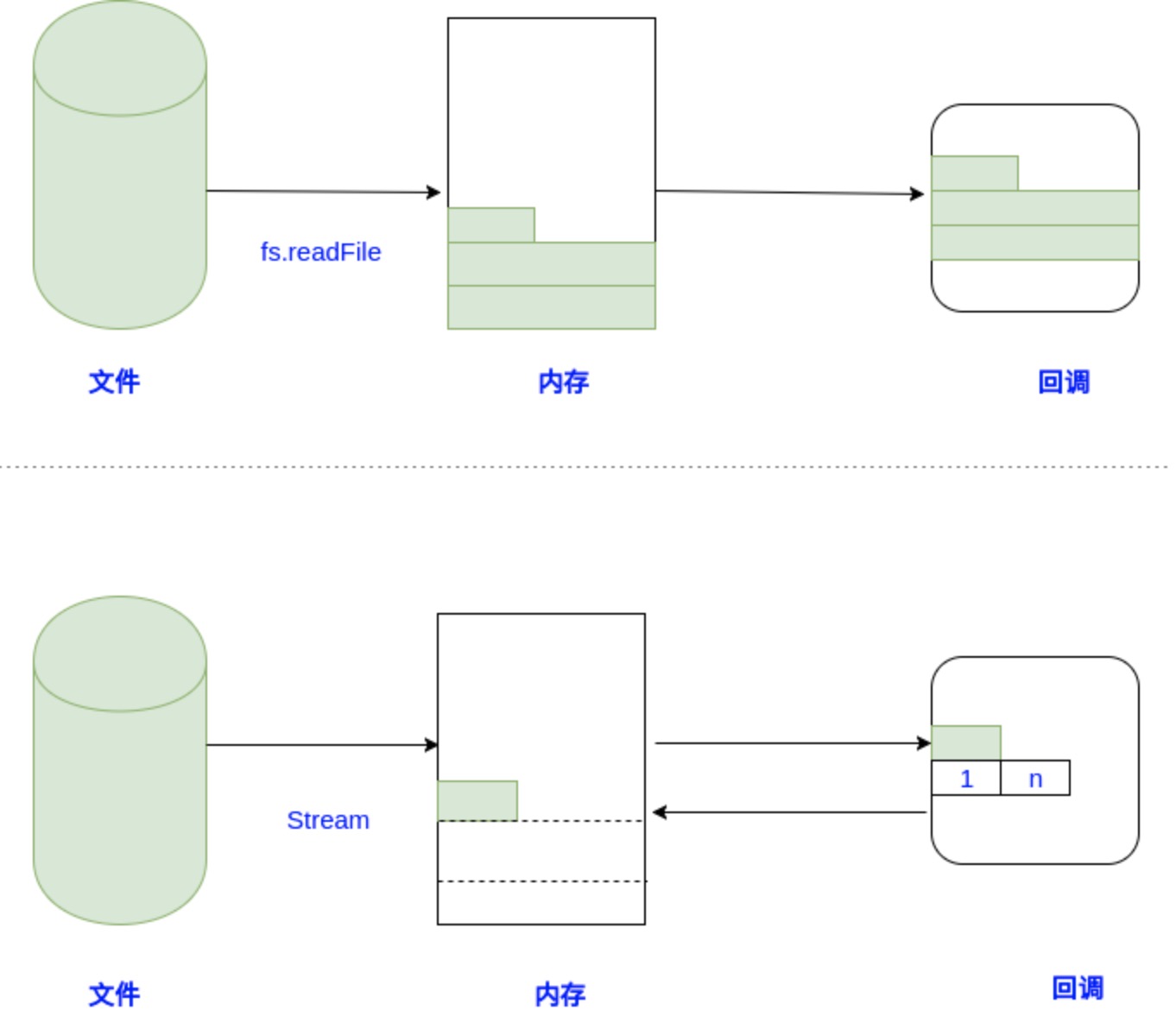
语言一般分为编译型语言和解释性语言
- 编译型语言:先编译在执行,例如做好饭在吃
大致步骤为:词法分析 -> 语法分析 -> 语义检查 -> 代码优化和字节码生成 - 解释性语言:涮火锅
大致步骤为:词法分析 -> 语法分析 -> 语法树,然后直接解释执行了
加深理解,学习了一下用js写一个解析器,转换成ast抽象结构树,在写编译器转换成汇编语言的过程。
包括下面几个功能:
- 解析
- 汇编代码生成
- 系统调用
解析
解析函数应该返回ast,一个代表输入的数据结构,比如我们想要1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
```javascript
module.exports.parse = function parse(program) {
const tokens = [];
let currentToken = '';
for (let i = 0; i < program.length; i++) {
const char = program.charAt(i);
switch (char) {
case '(':
// 递归
const [parsed, rest] = parse(program.substring(i + 1));
// 把已经解析好的塞入数组中
tokens.push(parsed);
// 置空剩余参数,因为递归
program = rest;
i = 0;
break;
case ')':
// 去掉多余的右括号
tokens.push(+currentToken || currentToken);
// return 直接阻止函数继续运行,直接返回
return [tokens, program.substring(i + 1)];
break;
case ' ':
// 遇到空格则全部塞入tokens
tokens.push(+currentToken || currentToken);
currentToken = '';
break;
default:
currentToken += char;
break;
}
}
// 如果第二个参数不为'',这解析过程有误
return [tokens, '']
}
简单测试:
1 | JSON.stringify(parse('(- 2 (+ 4 5))'), null, 0) // [[["-",2,["+",4,5]]],""] |
汇编相关
汇编使我们能使用的最低级的编程语言,是兼顾可读性和1:1对应相应二进制的,cpu可直接解释的语言。
可使用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86汇编主要的数据结构是寄存器(cpu存储的临时变量)和程序堆栈。程序中的每个函数都会访问相同的寄存器,但是也有一些更实用更耐用的寄存器,比如```RAX```、```RDI```等等。
来了解一下我们会用到的一些汇编功能:
- MOV:移动寄存器内容到另外一个,或者存储字面量到寄存器中
- ADD:合并两个寄存器的内容到第一个寄存器
- PUSH:将寄存器中的内容放置到堆栈中
- POP:移除堆栈里最顶层的内容,并存储到寄存器中
- CALL:访问堆栈中的一部分,并且开始执行
- RET:访问并调用一个堆栈并返回调用之后的下一个指令的评估
- SYSCALL:和call差不多,不过有```kernel```处理
#### 汇编代码生成
话不多说,上代码
```javascript
// 代码转换部分
function emit(depth, code) {
const indent = new Array(depth + 1).map(() => '').join(' ');
console.log(indent + code);
}
function compile_argument(arg, destination) {
// 如果是数组,则递归
if (Array.isArray(arg)) {
compile_call(arg[0], arg.slice(1), destination);
return;
}
// 否则直接存储代码
emit(1, `MOV ${destination}, ${arg}`);
}
const BUILTIN_FUNCTIONS = { '+': 'plus' };
const PARAM_REGISTERS = ['RDI', 'RSI', 'RDX'];
function compile_call(fun, args, destination) {
// 入栈
args.forEach((_, i) => emit(1, `PUSH ${PARAM_REGISTERS[i]}`));
// 递归
args.forEach((arg, i) => compile_argument(arg, PARAM_REGISTERS[i]));
// 执行部分
emit(1, `CALL ${BUILTIN_FUNCTIONS[fun] || fun}`);
// 出栈
args.forEach((_, i) => emit(1, `POP ${PARAM_REGISTERS[args.length - i - 1]}`));
// 如果提供,这转移到相应的寄存器
if (destination) {
emit(1, `MOV ${destination}, RAX`);
}
emit(0, ''); // 优化格式
}
function emit_prefix() {
// 常规前缀
emit(1, '.global _main\n');
emit(1, '.text\n');
emit(0, 'plus:');
emit(1, 'ADD RDI, RSI');
emit(1, 'MOV RAX, RDI');
emit(1, 'RET\n');
emit(0, '_main:');
}
const os = require('os');
const SYSCALL_MAP = os.platform() === 'darwin' ? {
'exit': '0x2000001',
} : {
'exit': 60,
};
function emit_postfix() {
// 常规后缀
emit(1, 'MOV RDI, RAX'); // Set exit arg
emit(1, `MOV RAX, ${SYSCALL_MAP['exit']}`); // Set syscall number
emit(1, 'SYSCALL');
}
module.exports.compile = function parse(ast) {
emit_prefix();
compile_call(ast[0], ast.slice(1));
emit_postfix();
};
简单测试:
1 | node ulisp.js '(+ 3 (+ 2 1))' |
整合并调用
我们可以将生成的汇编代码输出到文件中,并使用gcc进行调用
1 | $ node ulisp.js '(+ 3 (+ 2 1))' > program.S |
大概就是这样,中的来说可以对编译语言有一个浅显的理解,或许日后会用到
参考链接